Bug #1197
closed
network performance problems on VM hosts
Added by Christian Lohmaier about 11 years ago. Updated over 10 years ago.
0%
Description
currently connections to/from manitu hosts are horribly throttled/shaped to ~5MB/s maximum.
Start multiple transfers and you get x-times the rate. Especially for connections to dev-downloads (that hosts our 3-10GB a-piece bibisect archives) such an artificial limitation (a limit that kicks in despite the outgoing link is nowhere near being saturated) hurts a lot.
I didn't look yet where this limit is applied, might very well be at manitu's side (as we didn't manually setup any kind of traffic shaping/limiting)
simple testcase:
curl http://dev-downloads.libreoffice.org/bibisect/mac/Bibisect_MacOSX10.6%2b_release_lo-3.3.0_to_lo-4.1.tar.bz2 >/dev/null
from falco (where the vm is hosted): you get ~30MB/s (so it is not the VM's networking or load that is to blame)
and from pumbaa (you get around <5MB/s only, but if you do multiple ones, you get x-times that slow speed)
Same for copying files that are on falco itself, bypassing any VM-stuff.
Files
| df.png (95.9 KB) df.png | David Richards, 2015-04-28 14:11 | ||
| graph.png (12.9 KB) graph.png | cannot keep up the 100Mbit/s for the whole transfer | Christian Lohmaier, 2015-05-06 12:03 | |
| graph_manitu.png (9.3 KB) graph_manitu.png | full speed throughout to manitu host (galaxy) | Christian Lohmaier, 2015-05-06 13:01 | |
| graph_website.png (14.2 KB) graph_website.png | solid transfer to website host (only has 100Mbit network) | Christian Lohmaier, 2015-05-06 13:09 |
{kind=link}
 Updated by Florian Effenberger about 11 years ago
Updated by Florian Effenberger about 11 years ago
Was this better before, i.e. do we know of faster downloads from that
machine(s)?
I'm not aware of any limitation enforced by them and wonder if it might
e.g. be related to our firewall setup, or the VMs having emulated 100
Mbit/s NICS?
Can we compare IPv4 and IPv6, if that makes a difference?
Do we have the same speed problem when downloading something e.g.
directly from falco via SSH?
Is it just outgoing traffic, or is downloading some external source e.g.
from falco also slow?
Updated by Florian Effenberger about 11 years ago
I tried downloading http://speedtest.netcologne.de/test_1gb.bin to
dauntless, and it yields about 20 MB per second, Hetzner gives twice as
much.
Downloading that from manitu to Hetzner only gives about 6 MB/s (I
didn't check the network saturation on dauntless though)
For
ftp://ftp.halifax.rwth-aachen.de/opensuse/distribution/13.2/iso/openSUSE-13.2-Rescue-CD-i686.iso
it looks even more different - Hetzner giving 70 MB per second, manitu
only 20
Downloading to vm168, only connected with 100 Mbit/s, gives nearly the
full rate of 10 MB/s.
Downloading from vm168 to pumbaa seems to give more than 6 MB/s, about 9
MB/s.
So either it's related to the big boxes shaping/switch, or a possible
firewall - right now it seems the regular web server gives faster
download than the big boxes
Updated by Florian Effenberger about 11 years ago
Can that be somehow related to the bridge setup?
As some last resort, we could take down one host that only runs test
stuff (if we have it), and see how fast things are in the rescue system
Updated by Christian Lohmaier about 11 years ago
it is not related to the VM configuration
as mentioned in the initial description: downloading the bibisect repo from falco itself (where the VM runs on) yields 30MB/s - so the virtual network or configuration of the VM (disk, nginx,....) is not the bottleneck here.
Also even if you take the VMs out of the question and try to e.g. copy one of the virtual disk images to another host via the external network, you get the same effect (also mentioned in the initial description :-)
it is not a new problem
I always thought that networking on the manitu hostes VMs is slow - but back then I didn't know whether it was glusterfs-syncing or other stuff interfering with the network - I never was happy with the speed I got when working with the dev-downloads' bibisect repos
only outbound affected
inbound, i.e. from falco itself, there doesn't seem to be any artificial limits (way more than 10x the outbound speed)
can confirm that the vm168 host yields better rate at around 9MB/s
the point is that using multiple transfers, gives a higher overall rate.
I installed aria2 on pumbaa to demonstrate:
aria2c http://dev-downloads.libreoffice.org/bibisect/mac/Bibisect_MacOSX10.6%2b_release_lo-3.3.0_to_lo-4.1.tar.bz2
→ intially displays 10MiB/s, then quickly drops to settle at less than 5MiB/s (~4.5)
aria2c -x 3 http://dev-downloads.libreoffice.org/bibisect/mac/Bibisect_MacOSX10.6%2b_release_lo-3.3.0_to_lo-4.1.tar.bz2 # (allow up to 3 connections per server)
→ downloads with ~ 12MiB/s
If at all, we could use dauntless for a test, as there we only need to wait until a testrun is complete, and then can take it down for a short while.
Updated by Florian Effenberger about 11 years ago
Thanks for the summary!
I'm on the road the next two days, but using dauntless (ideally during
manitu's office hours, so tomorrow from ~8/9 to ~1700) for a test drive
sounds worthwhile I guess, just so we can rule out any local setup issue
Firewall doesn't seem to run on the hosts. By testing via the rescue
system we could gather new details (hopefully)
Updated by Christian Lohmaier about 11 years ago
curl http://ftp-stud.hs-esslingen.de/pub/Mirrors/Mageia/iso/4.1/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD.iso >/dev/null
send to /dev/null to avoid any limits imposed by underlying disk-setup/measure raw network performance (the iso is 1458M)
pumbaa:
Average Dload: 85.2M (→ hs-esslingen has plenty of bw/is not limiting factor)
dauntless:
Average Dload: 30.6M (→ kind of disappointing in comparison, but still OK)
curl http://ftp.snt.utwente.nl/pub/linux/mageia/iso/4.1/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD.iso >/dev/null
pumbaa
Average Dload: 31.6M (→ utwente (has 10GB-network) doesn't let single users have all their BW :-))
dauntless
Average Dload: 8108k (→ pathetic, not even close to what pumbaa gets, and not even close to the 30M with the other mirror, the "upper limit")
dauntless (rescue system)
Average Dload: (esslingen): 30.9M (→ within margin of error)
(utwetnte): 7314k (→ even worse, but routing/... to blame - still order of magnitude lower BW than from hetzner Server)
Other tests
rsync -ahP root@dauntless:mageia.iso ./ (on pumbaa) 15.06M bytes/sec (meh)
(on excelsior) 40.77M bytes/sec (yay)
so manitu-internal networking is not throttled, but outgoing to pumbaa/Hetzner is not even half that speed.. Network interfaces on both the manitu hosts could easily handle > 30MB/s
→ it is not the boxes themselves where the throttling occurs, it is in the following hops where bandwidth is lost.
dauntless (bridge/regular):
on excelsior: 36.84MB/s (hmm - quite some impact, but still OK, maybe excelsior was busier at the time)
on pumbaa: 5.14MB/s (wow, only third of what you get with rescue system....)
→ bridged networking has some negative impact it seems, but the difference inbound/outbound is rather large. Also difference in inbound traffic with different servers is kind of unsettling.
Either manitu's networking is saturated, or traffic-shaping is applied. Either of the two is bad.
combined networking: (i.e. multiple connections) test in /run/shm - to avoid limits imposed by disk-io/similar):
aria2c http://ftp5.gwdg.de/pub/linux/mageia/iso/4.1/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD.iso http://ftp-stud.hs-esslingen.de/pub/Mirrors/Mageia/iso/4.1/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD.iso http://ftp.uni-erlangen.de/mirrors/Mageia/iso/4.1/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD/Mageia-4.1-LiveDVD-GNOME-x86_64-DVD.iso
I.e. using three fast mirrors simultaneously → only 33.8MiB/s from dauntless (77,7MiB/s from pumbaa - less than with just esslingen mirror, as the other have lower per-connection limits, but all allow for >50MB/s individually)
Summary
Inbound bandwidth is capped at around 30MiB/s
outbound bandwidth doesn't even get close to that, fluctuating quite a bit, but on average around 5MB/s
As transfers between manitu hosts (still using the external network) reach the 30MiB/s, it is unlikely that the host's own setup is to blame, but rather manitu's outbound rules throttle the transfers.
transfer to pumbaa while in rescue system was significantly faster (with around 15MB/s), but still far from what you'd expect from a 1GB link that is otherwise idle.
Transfer is not only slow to hetzner-based servers, but also e.g. to gimli or to amazon ec2 hosts (that's where I first noticed slow outbound traffic - uploading tinderbox builds to gimli from VMs on manitu server or downloading bibisect repos to ec2 from VM on manitu) - gimli can easily handle >20MB/s from e.g. pumbaa, but from manitu (no matter whether host or vms running on the hosts) you get ~5MB/s only)
Updated by Florian Effenberger about 11 years ago
Hm, that's quite odd indeed, and we should raise this with manitu support
Thanks for checking this!
Alex, maybe let's have a quick chat first before approaching manitu
Updated by Alexander Werner about 11 years ago
This may also be related to the random monitoring plugin timeouts - no other reason could be found by me so far, so it might be related to generic connection problems.
Updated by Alexander Werner about 11 years ago
Some ping statistics can now be found here: https://monitoring.documentfoundation.org/smokeping/smokeping.cgi?target=manitu
Updated by Alexander Werner about 11 years ago
Setting connection speed to 100MBit to check for driver/kernel problems.
Updated by Florian Effenberger about 11 years ago
- Status changed from New to In Progress
Updated by Florian Effenberger about 11 years ago
- Subject changed from get rid of per-connection bandwidth limits on manitu hosts to investigate network driver issues with Debian kernel for Gbit/s connectivity
Updated by Florian Effenberger about 11 years ago
- Priority changed from Low to Normal
Updated by David Richards about 11 years ago
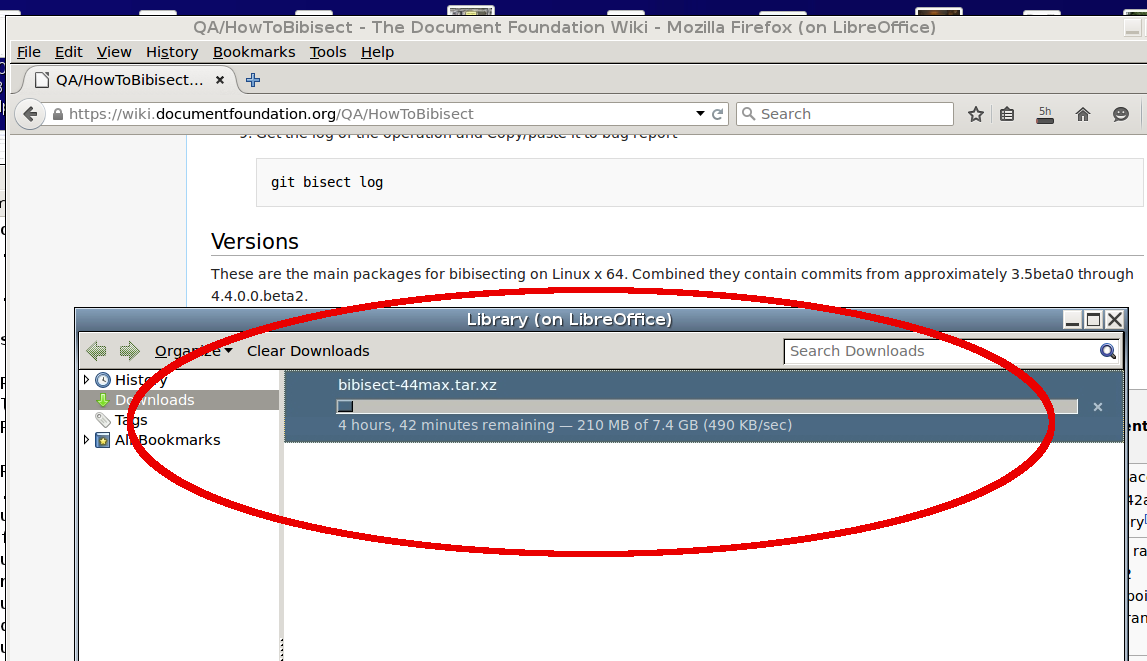
I have been trying to download 44max to help bibisect from Florida/US for the last few days and continue to get the same slow connection. The connection mostly sits 200KB/sec to 500KB/sec. We are on an enterprise 50Mb Internet circuit. Looks like it will finish today during my work hours, but wanted to bring it to your attention.
Updated by Alexander Werner about 11 years ago
- Due date set to 2015-05-08
- Status changed from In Progress to Feedback
Ethernet connection speed was set to 100baseTx-FD on dauntless manually, now its necessary to see if network behaves differently.
Updated by Christian Lohmaier about 11 years ago
with the limit to 100Mbit the transfer rates are better on average, but there are still quite significant fluctuations in transfer rate to servers outside manitu (outside of our manitu hosted servers to be exact).
While I get full speed on a transfer from dauntless to falco, trying the same from one of our hetzner based servers suffers from speed-drops throughout the transfer. It starts with full speed, but after 200 or so MB transfers, the rate drops, then recovers to full speed and drops again. Attached is a plot of the transfer rates that did yield in one of the better averages, but still demonstrates the problem of not being able to deliver full speed throughout the transfer.
Updated by Florian Effenberger about 11 years ago
Thanks for testing! Is that also true for the regular root servers
(galaxy, website), or is the speed constant there?
Updated by Christian Lohmaier about 11 years ago
- File graph_manitu.png graph_manitu.png added
- File graph_website.png graph_website.png added
Speed to galaxy is full-speed throughout:")
website host is nearly fullspeed (but that host is under load right now, so wouldn't expect it to reach maximum) - and that host only has 100MBit connectivity to begin with. The important part is that there are no significant dropouts during the transfer.")
Updated by Florian Effenberger about 11 years ago
Any chance to test this also with falco and excelsior, to see if they suffer the same issues, for the big picture?
Updated by Alexander Werner almost 11 years ago
First update dauntless to debian 8.0
Updated by Florian Effenberger almost 11 years ago
- Blocks Task #1315: Bare Metal Debian 8 migration added
Updated by Florian Effenberger almost 11 years ago
Notes from last infra call:
* Inspect packages from machine-machine and machine-internet * Get stats from kernel * Test if problem persists after upgrade to Debian 8 on dauntless
Updated by Florian Effenberger almost 11 years ago
- Blocks deleted (Task #1315: Bare Metal Debian 8 migration)
Updated by Florian Effenberger almost 11 years ago
- Tracker changed from Task to Bug
- Subject changed from investigate network driver issues with Debian kernel for Gbit/s connectivity to network performance problems on VM hosts
- Due date deleted (
2015-05-08) - Status changed from Feedback to In Progress
- Priority changed from Normal to Urgent
With the migration of bilbo to the new VM planned in Q4, we need to escalate this. Debian 8 didn't bring any benefit - we should inspect the kernel logs and packets, and if that fails, ask manitu for a different NIC (Intel?).
Updated by Florian Effenberger almost 11 years ago
- Blocks Task #825: migration of bilbo to VM platform added
Updated by Florian Effenberger almost 11 years ago
- Blocks Task #824: migration of kermit to VM platform added
Updated by Florian Effenberger over 10 years ago
- Target version changed from Pool to Q4/2015
Updated by Florian Effenberger over 10 years ago
- Priority changed from Urgent to Normal
Updated by Florian Effenberger over 10 years ago
related to #995
when we have feedback, plan is to replace WAN card(s) and see how things go; most likely a switch of the NIC will help
Updated by Florian Effenberger over 10 years ago
- Target version changed from Q4/2015 to Q1/2016
Updated by Alexander Werner over 10 years ago
- Status changed from In Progress to Closed
Dual 10GBaseT cards for our Hypervisors are ordered, one of the ports will be used for the public interface.
Closing as #995 is the succeeding issue.
Updated by Florian Effenberger almost 9 years ago
- Blocks deleted (Task #824: migration of kermit to VM platform)
Updated by Florian Effenberger almost 9 years ago
- Blocks deleted (Task #825: migration of bilbo to VM platform)